
Publications 2019-2023
Locking On: Leveraging Dynamic Vehicle-Imposed Motion Constraints to Improve Visual Localization [IROS 2023]
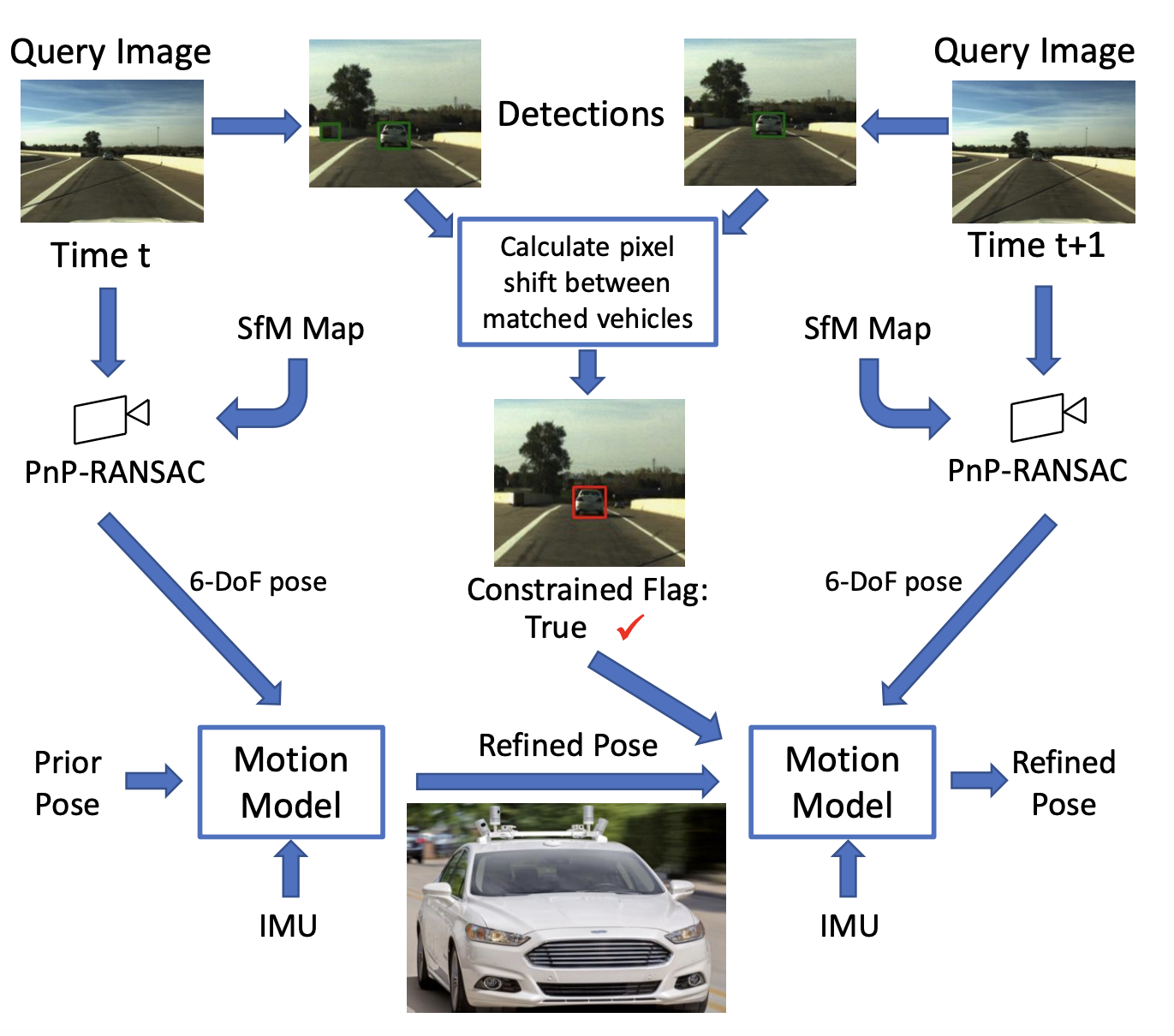
Method for 6-DoF localization of autonomous vehicles using a frontal camera, where dynamic vehicles help with the localization by providing partial pose constraints. Compared to traditional techniques, this approach significantly boosts localization accuracy within a range of 0.25m to 5m, especially when the system is actively detecting dynamic vehicles.
DisPlacing Objects: Improving Dynamic Vehicle Detection via Visual Place Recognition under Adverse Conditions [IROS 2023]
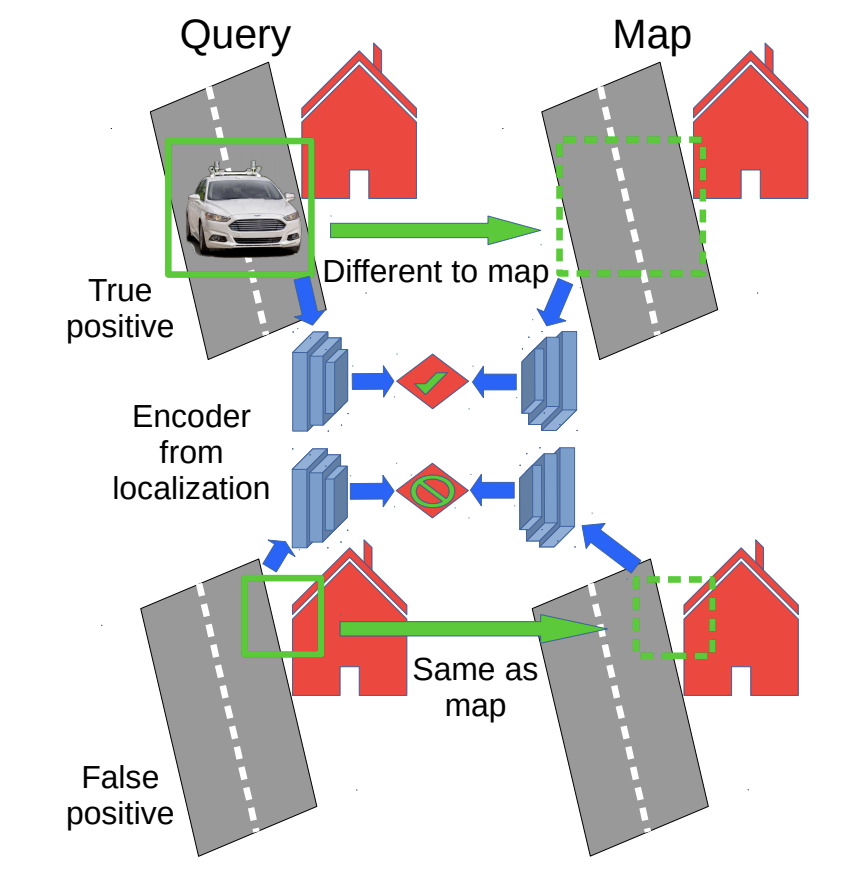
Can knowing where you are assist with object detection for Autonomous Vehicles? We show that a prior map can be leveraged to aid in the detection of dynamic objects in a scene without the need for a 3D map or pixel-level map-query correspondences.
Mitigating Bias in Bayesian Optimized Data While Designing MacPherson Suspension Architecture [IEEE Transactions on AI, 2023]

Can we use AI to influence automotive design? This paper uses the car’s desired kinematic characteristics, and Bayesian optimization to circumvent the industry standard of hand designed parameters. We achieve partial automation of the design process by employing a multi-body dynamics simulation model and allowing the Bayesian optimization to iteratively explore the design space without human intervention.
RADIANT: Radar-Image Association Network for 3D Object Detection [NeurIPS 2022]
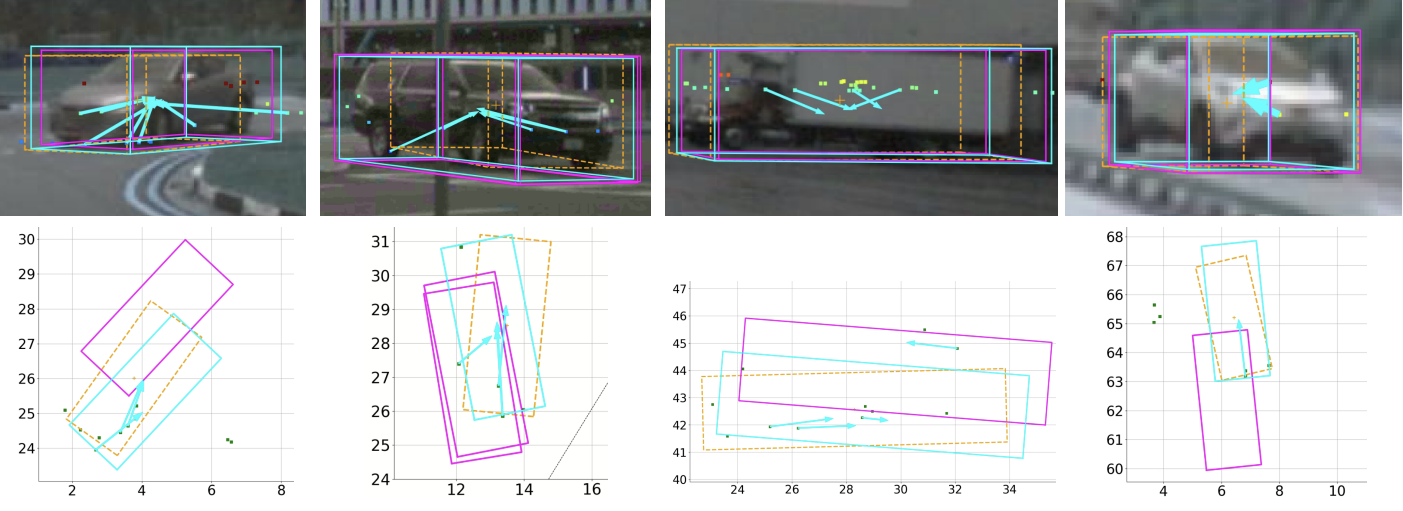
This paper presents a novel radar-camera fusion approach for 3D object detection. Radar can help with monocular 3D object detection but it is difficult to associate sparse radar returns with monocular 3D estimates of bounding boxes. The network described in this paper predicts the 3D offsets between radar returns and 3D object centres using parallel radar and camera branches. Experiments on NuScenes show significantly improved MAP and ATE over its monocular counterparts.
FQDet: Fast-converging Query-based Detector [NeurIPS 2022]
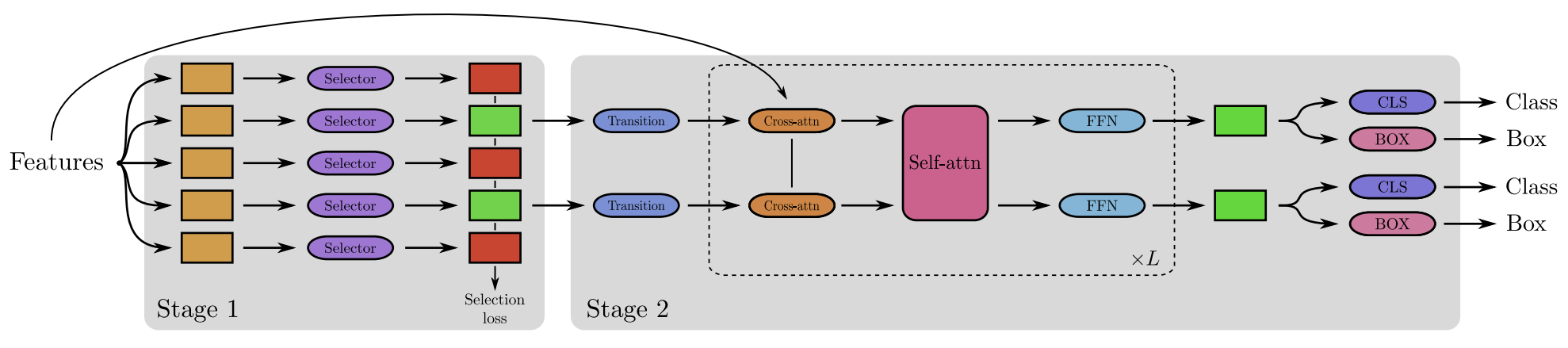
This work speeds up the training of Deformable DETR by improving the query-based 2-stage detector head with anchor-based techniques. A first stage comprising of a backbone network outputs region proposals, which are treated as queries in a second stage transformer network, which is trained to output bounding boxes and classes. It outperforms other 2-stage heads like Cascade RCNN while using the same backbone, and being computationally cheaper. FQDet head achieves 52.9 AP on the 2017 COCO test-dev set after only 12 epochs of training.
Look Both Ways: Bidirectional Visual Sensing for Automatic Multi-Camera Registration [ARXIV 2023]
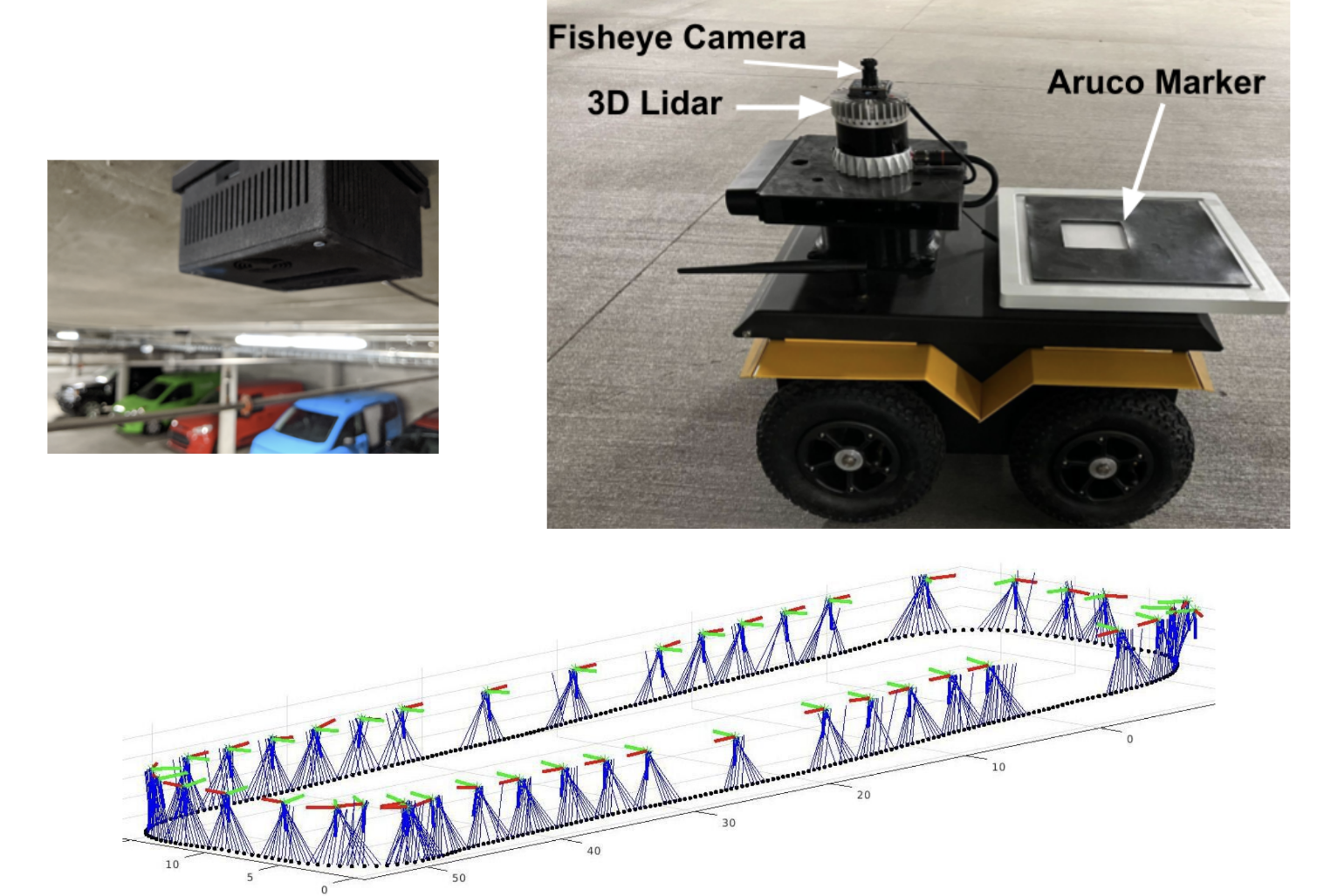
This work describes the automatic registration/calibration of 40 fixed ceiling mounted cameras covering ~800 square meters using a mobile robot. The robot has an upward facing fisheye camera and uses it for visual odometry/SLAM and also for detecting the overhead cameras. Each overhead camera has its own processing and is able to detect the robot and its relative pose. Bidirectional detection between the robot and each ceiling-camera constrains the poses of both the robot and camera in a joint optimization process. This enables the automatic registration of large-scale multi-camera systems for surveillance or driving AVs and robotics within an indoor facility. The camera-only method provides a cheap, light and low power calibration approach, is validated with real experiments and compared to a LIDAR based approach.
Improving Worst Case Visual Localization Coverage via Place-Specific Sub-Selection in Multi-Camera Systems [IEEE RAL, ICRA 2022]
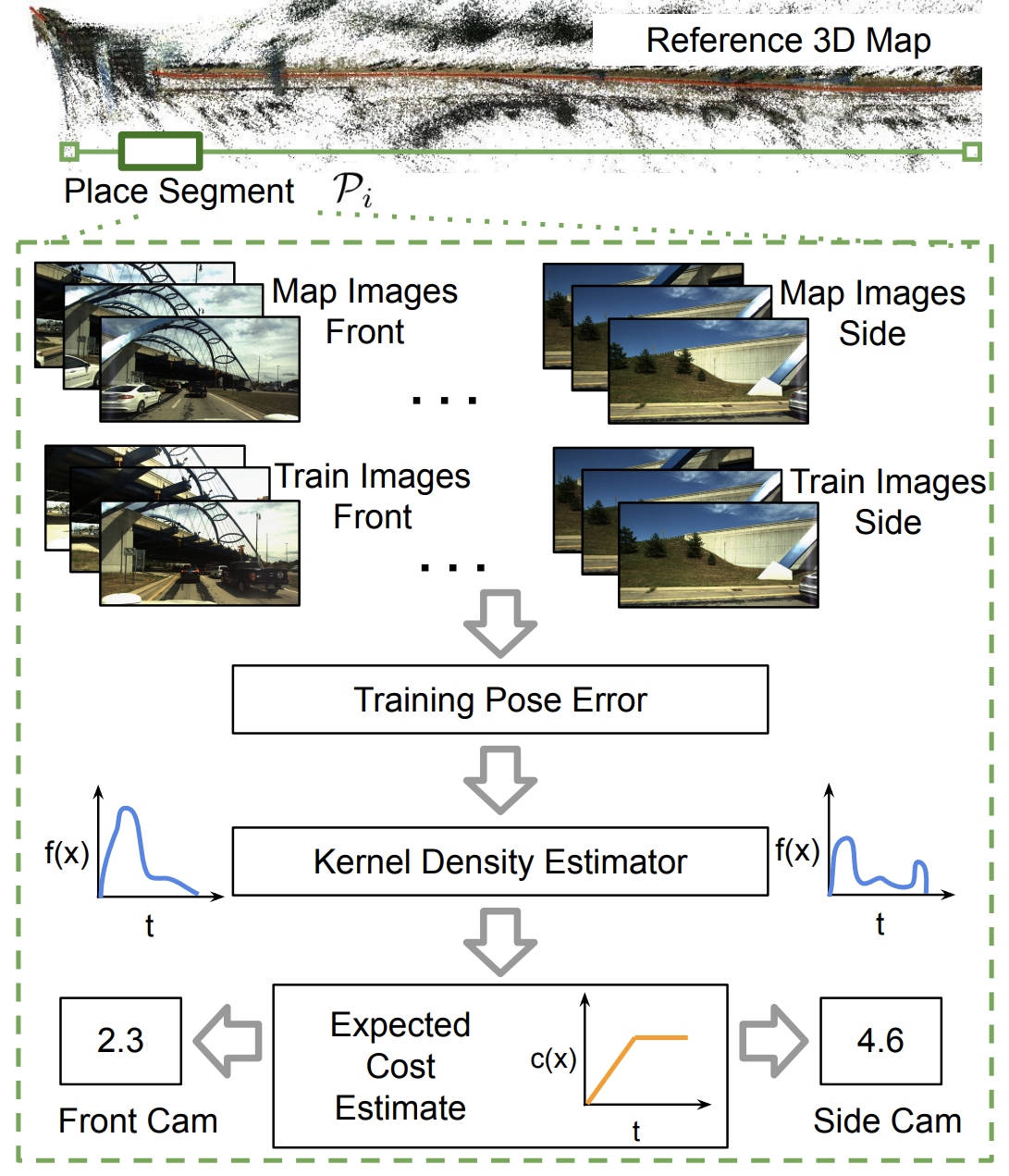
What if your AV fleet traverses the same route again and again? Can you take advantage of this for visual localization? This paper shows that you can. Current visual localization techniques struggle with insufficient recall at required error tolerances in challenging areas. This paper shows that selecting place-specific configurations, in terms of camera selection (for an AV with cameras in multiple directions) substantially improves worst-case localization on the Ford AV benchmark dataset.
Real-time Full-stack Traffic Scene Perception for Autonomous Driving with Roadside Cameras [ICRA 2022]

This work demonstrates a roadside traffic detection system. Pole mounted fisheye and thermal cameras and embedded compute are used for Infrastructure-Assisted autonomous driving. The system can be trained on 2D visual landmarks, but outputs 3D vehicle pose estimates and tracks. The system is deployed at a two-lane roundabout at Ellsworth Rd. and State St., Ann Arbor, MI, USA, providing 7×24 real-time traffic flow monitoring and high-precision vehicle trajectory extraction.
Propagating State Uncertainty Through Trajectory Forecasting [ICRA 2022]
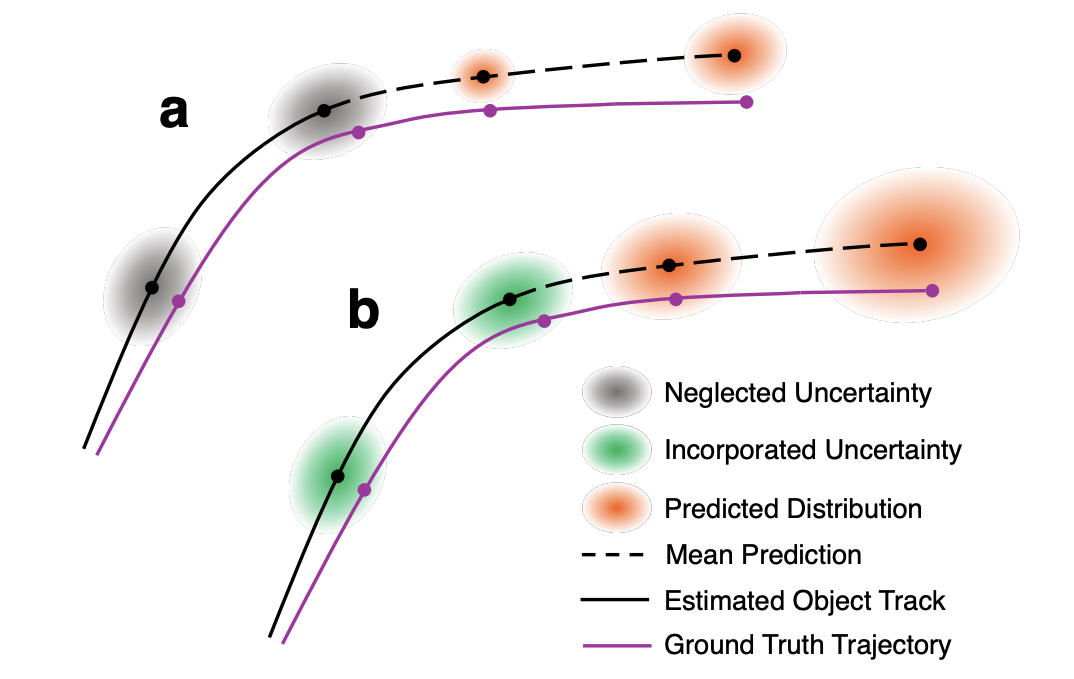
Existing trajectory forecasting methods for AVs do not account for upstream uncertainties from noisy perception. Object detection values are used, without account for uncertainty, resulting in overconfident trajectory predictions. This paper takes into account perception uncertainties by using a statistical distance based loss function to train the trajectory forecaster to match its predicted uncertainties with the upstream object detection uncertainty.
Localization of a Smart Infrastructure Fisheye Camera in a Prior Map for Autonomous Vehicles [ICRA 2022]
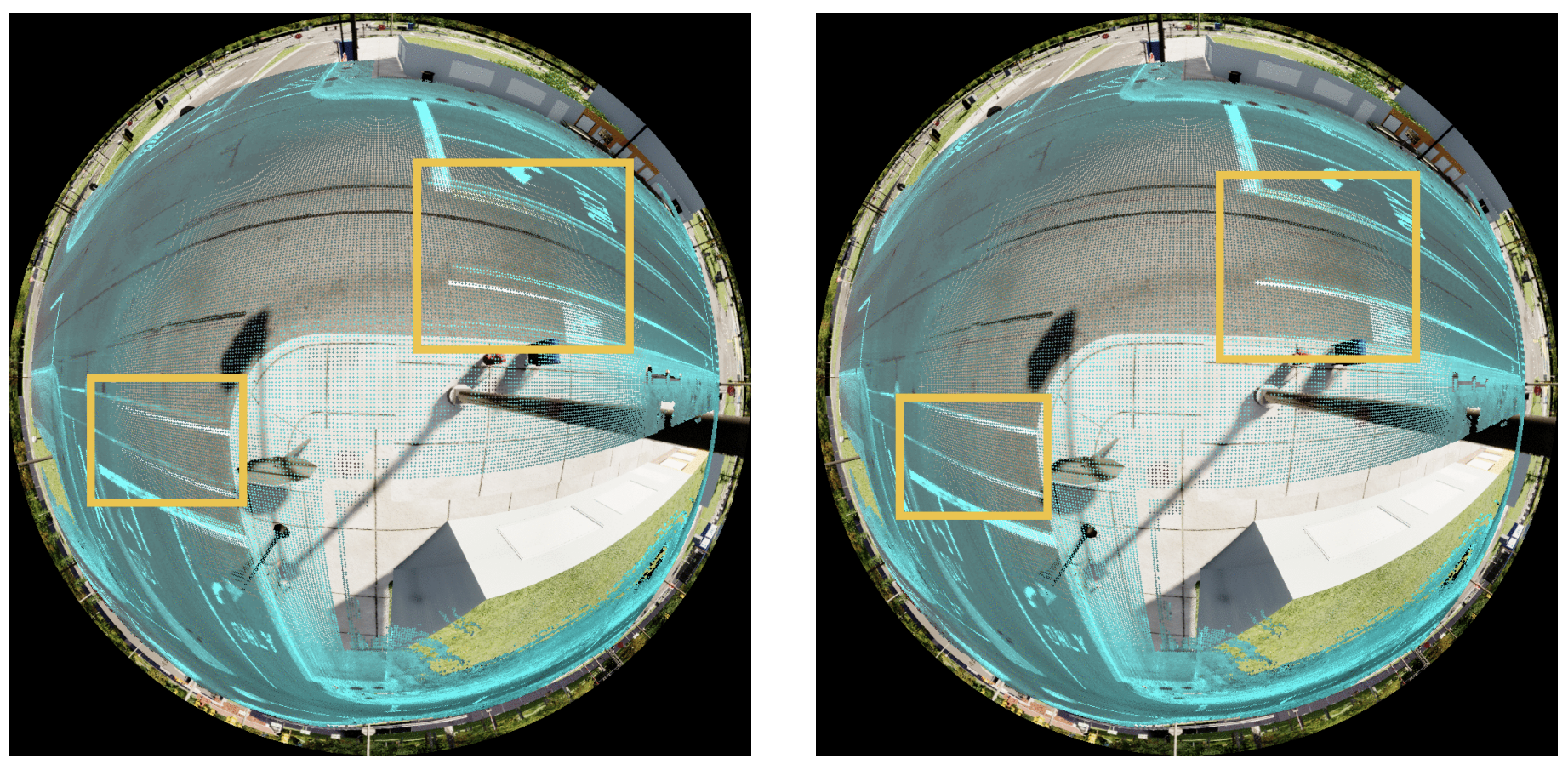
In this paper, we show that we can localize the pose of infrastructure-mounted cameras from satellite imagery. These fisheye cameras mounted on poles at intersections, can see beyond an AV’s field of view to alert it to objects beyond its line of sight. For this to be useful, these cameras have to be placed in the same map reference frame as the AV. Features are matched between satellite/aerial imagery and the fisheye images to estimate an initial pose, which is refined using a mutual information measure between the fisheye intensities and LIDAR reflectivity in the AV’s HD map.
Infrastructure Node-based Vehicle Localization for Autonomous Driving [ARXIV, 2021]
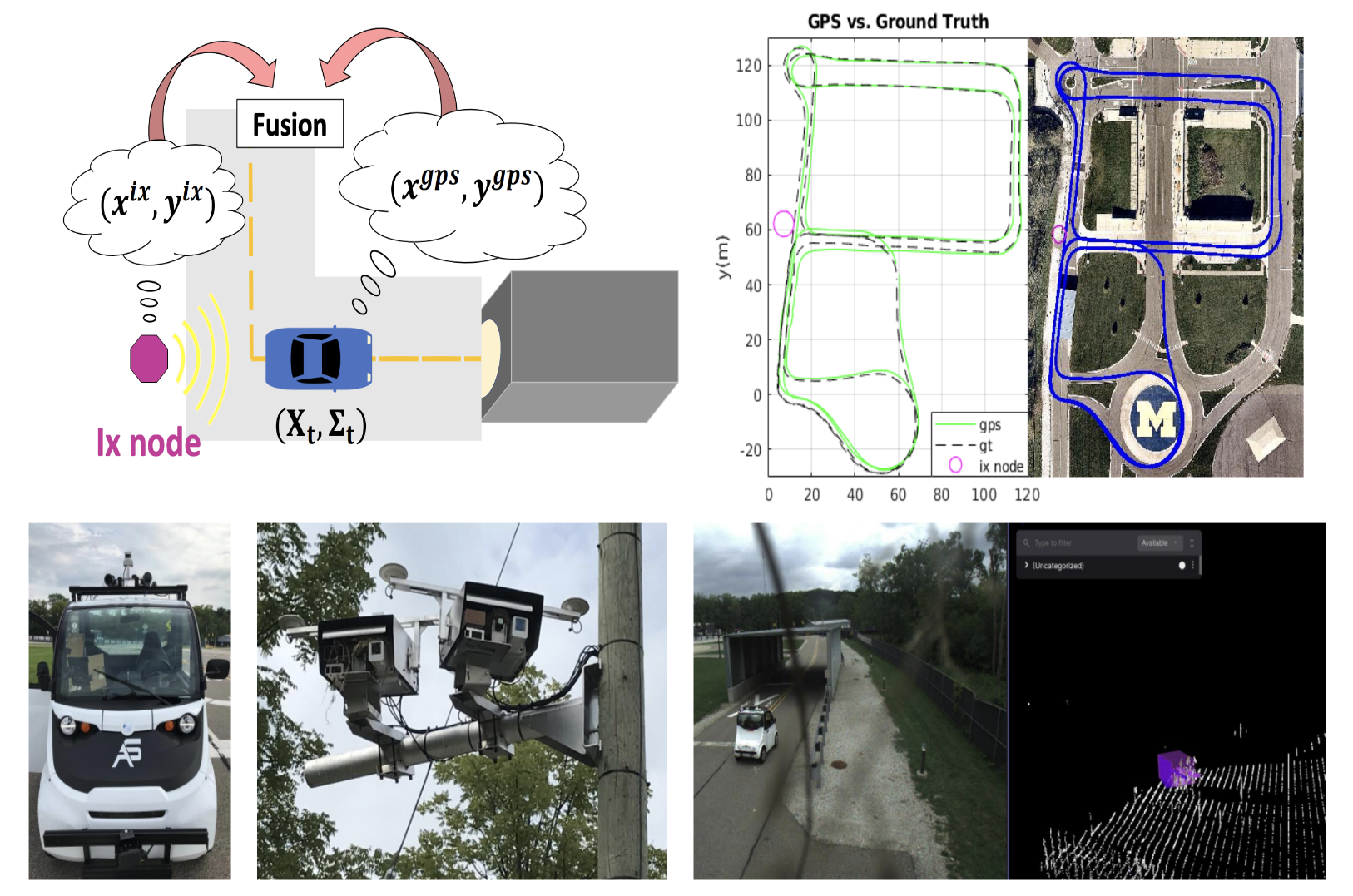
In this work, we develop a framework to use infrastructure (IX) mounted nodes (cameras+LIDAR+compute) to assist the localization of an AV. There are situations when an AV’s on-board sensing is blocked – for example in high traffic situations the landmarks that it normally uses for localization are not visible. The proposed approach fuses the on-board localization with the localization of the AV from the external IX nodes. The method is tested at MCity in Ann Arbor, showing improved localization with IX-assist.
Can We Localize a Robot/AV from a Single Image? Deep-Geometric 6 DoF Localization in Topo-metric Maps [Journal of AVs and Systems, 2021]
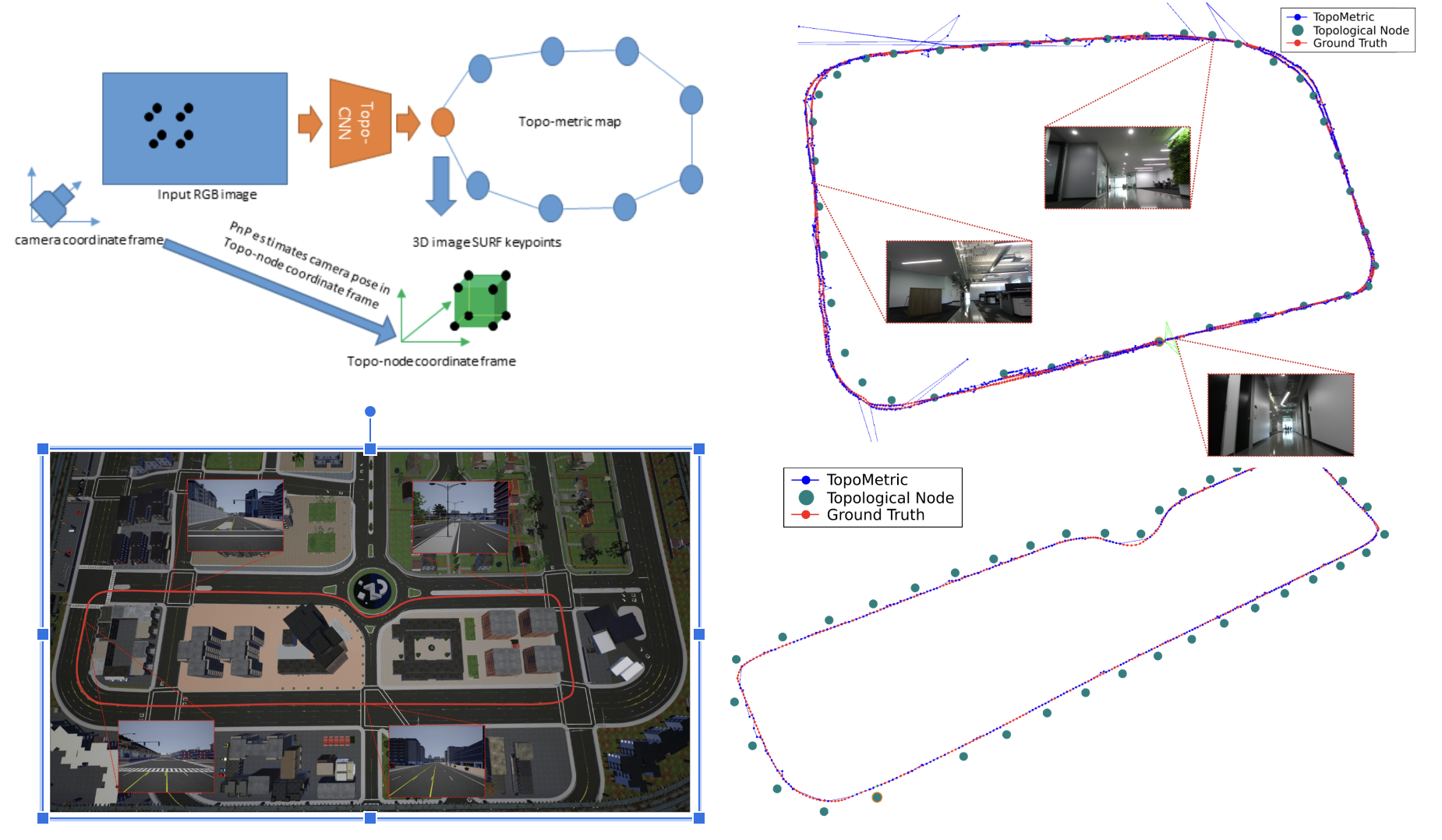
In this paper, we describe a Deep-Geometric Localizer that estimates full 6 DoF pose of a robot/AV from a single image in a mapped environment. The map contains topological nodes with known 6 DoF poses and 2D-3D point features. Localization matches an input image from the frontal camera to a node in the environment using Deep-learnt features and then uses PnP on the node’s 2D-3D features to get the 6 DoF pose of the camera. This compares favorably to SoTa for VR/AR, AV/drone/robot applications.
What My Motion tells me about Your Pose: A Self-Supervised Monocular 3D Vehicle Detector [ICRA 2021]
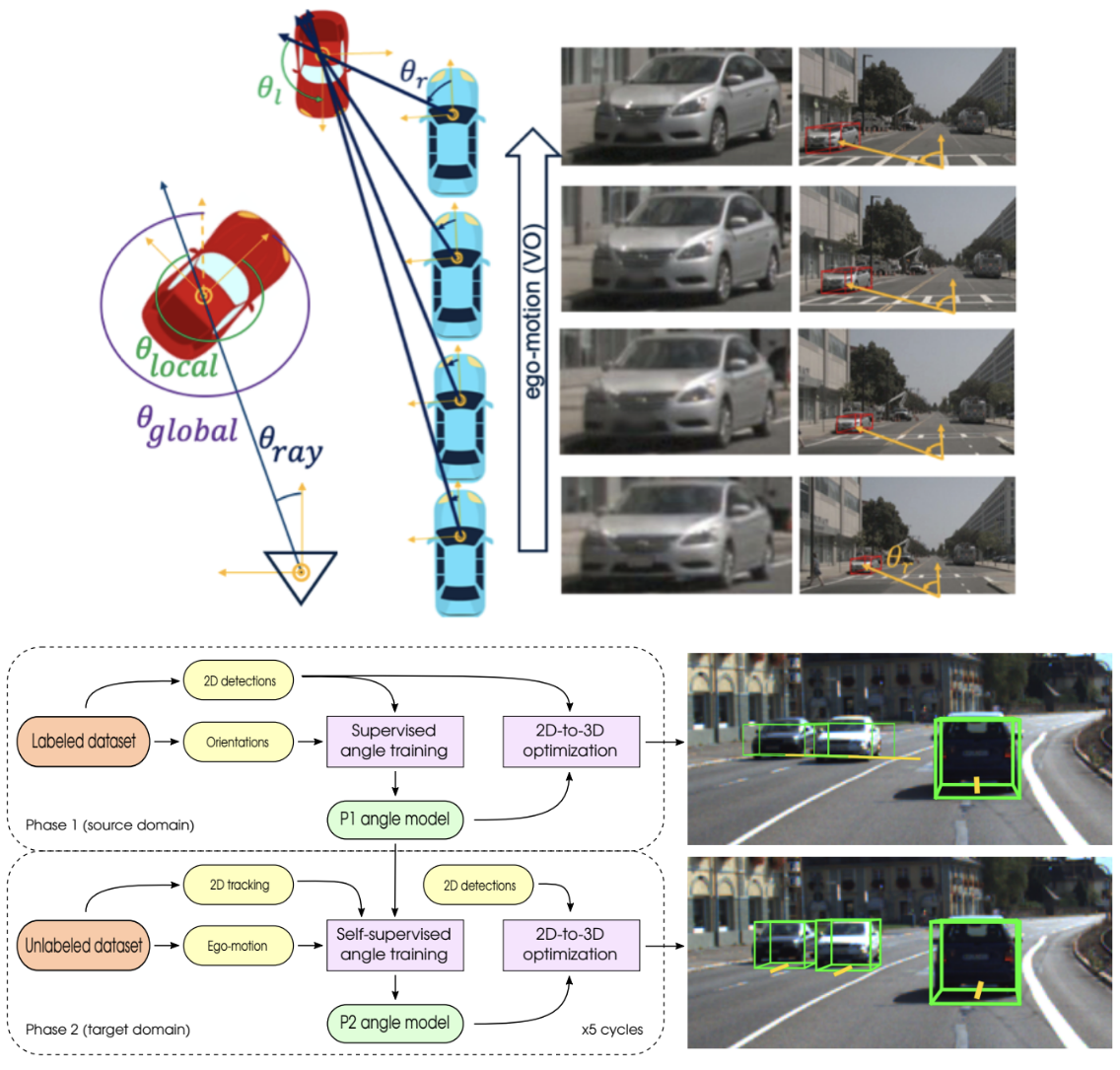
Estimating the orientation of an observed vehicle relative to an AV’s monocular camera data is important for 6 DoF object detection and safe autonomous driving. Current DL solutions for placing a 3D bounding box around this observed vehicle are data hungry and do not generalize well. This paper demonstrates the use of monocular VO for the self-supervised fine-tuning of a model for orientation estimation pre-trained on virtual data. Specifically, we recover upto 70% of the performance of a fully supervised method while going from virtual KITTI to NuScenes. This allows 3D vehicle detection algorithms to be self-trained from large amounts of monocular camera data from existing fleets.
S-BEV: Semantic Bird’s Eye View Representation for Weather and Lighting Invariant 3-DoF Localization [ARXIV, 2021]
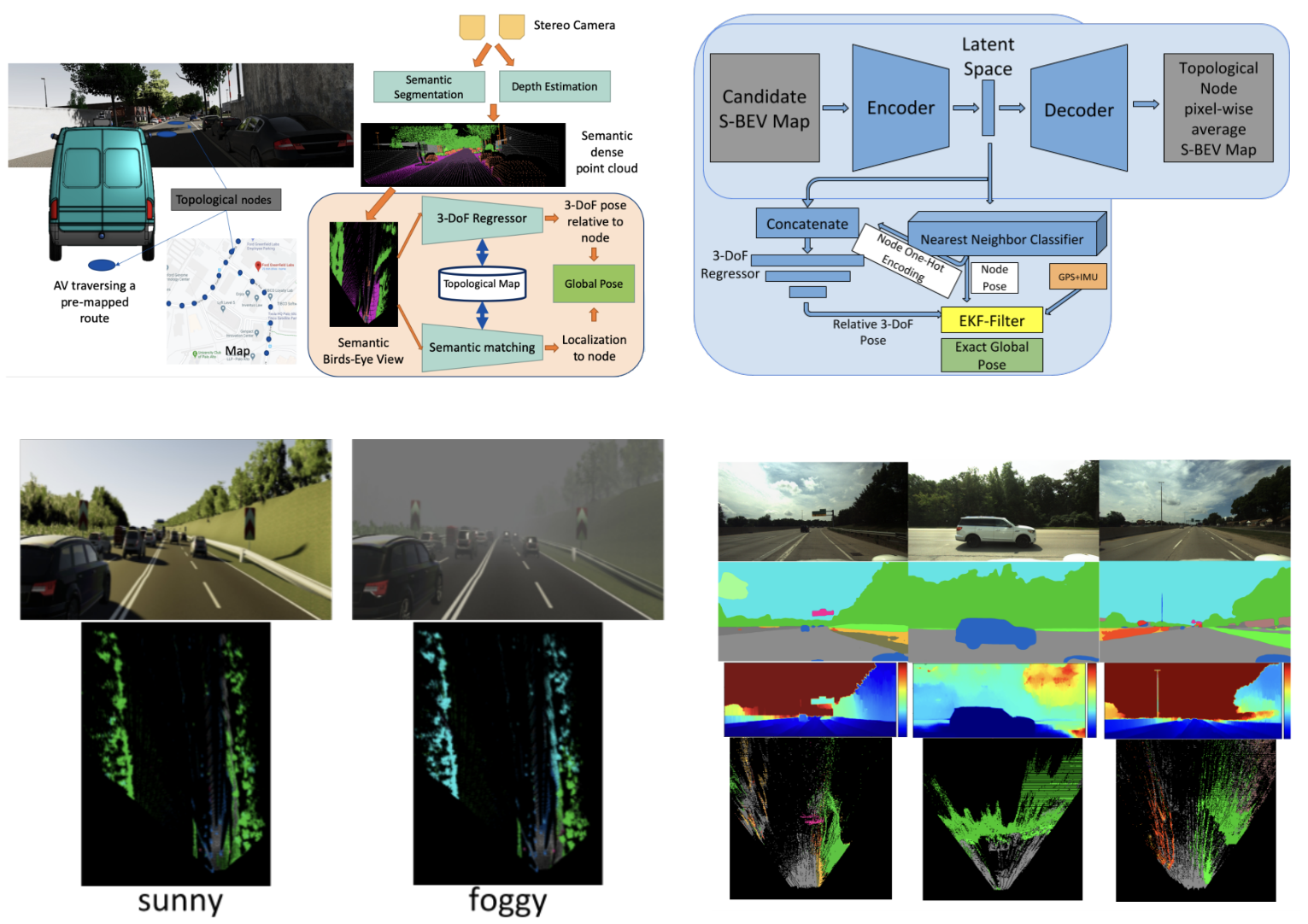
This paper describes a system for a lighting and weather invariant visual localization system. During a separate mapping state, a stereo camera and semantic segmentation is used to create semantic bird’s eye view (SBEV) data and signatures for each topological node in the map. During localization, a network is used to estimate the 3-DoF pose of the incoming SBEV to the topological node. An EKF smoothes this to give consistent, global pose estimates over time even in inclement weather. Results are shown along 22 km of a highway route in the Ford AV dataset.
An A* Curriculum approach to Reinforcement Learning for RGBD Indoor Robot Navigation [ARXIV, 2021]
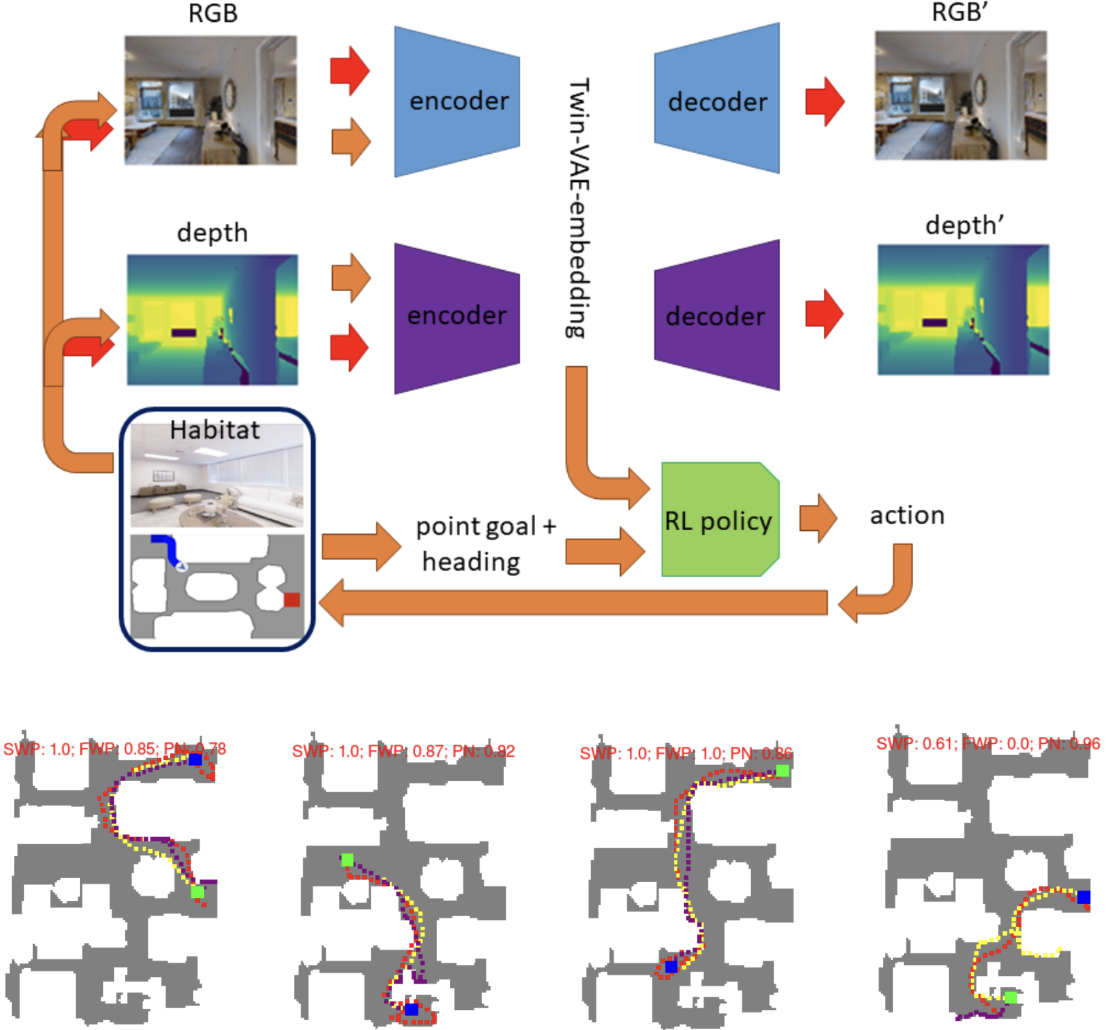
Training home robots to navigate diverse indoor environments is a challenging task involving mapping, localization and path-planning. Simulators like Habitat allow end-to-end training from images to control via deep reinforcement learning (RL), but this is data inefficient. This paper proposes separating the perception and control training. A twin-VAE is pre-trained to compress RGBD data into latent embeddings, which are subsequently used to train the DRL Proximal Policy Optimization (PPO) policy. A traditional path-planing A* algorithm provides guidance for this training in an incremental, curriculum manner where the RL policy is trained to navigate longer and longer paths in the house. This could be used to enable quick deployment of robots around the house and in the factory.
Radar-camera Pixel Depth Association for Depth Completion [CVPR, 2021]
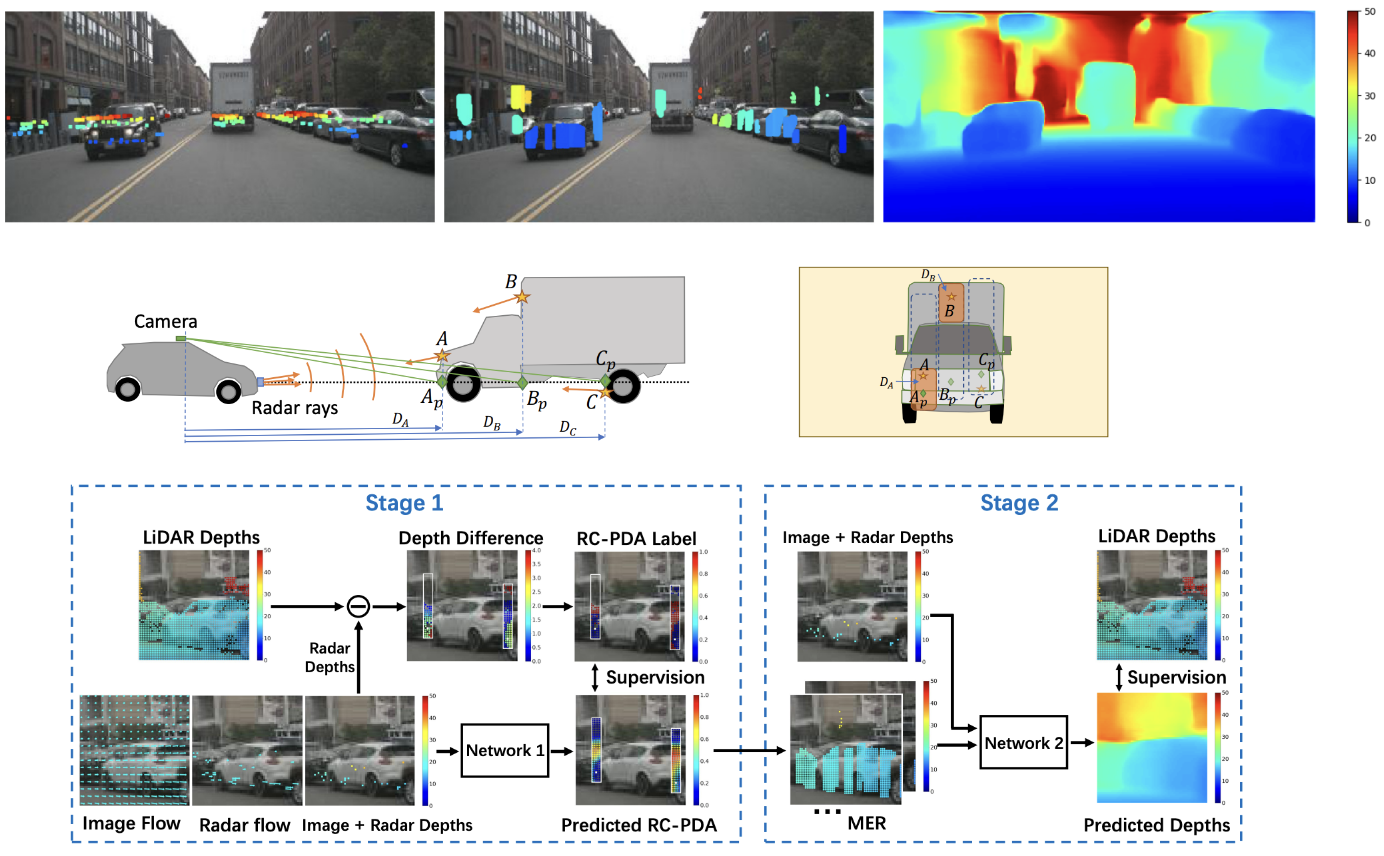
Automotive radar is sparse with beams much wider than a single camera image pixel, and the baseline between camera and radar is typically large, leading to problems in fusing the data at the pixel level. We propose a radar-camera-pixel associator that learns a mapping from radar returns to pixels and also densifies the radar return. This is followed by a more traditional depth completion method. Our results for radar-guided image depth completion on nuScenes are superior to camera or radar alone.
Full-velocity Radar Returns by Radar-Camera Fusion [ICCV, 2021]
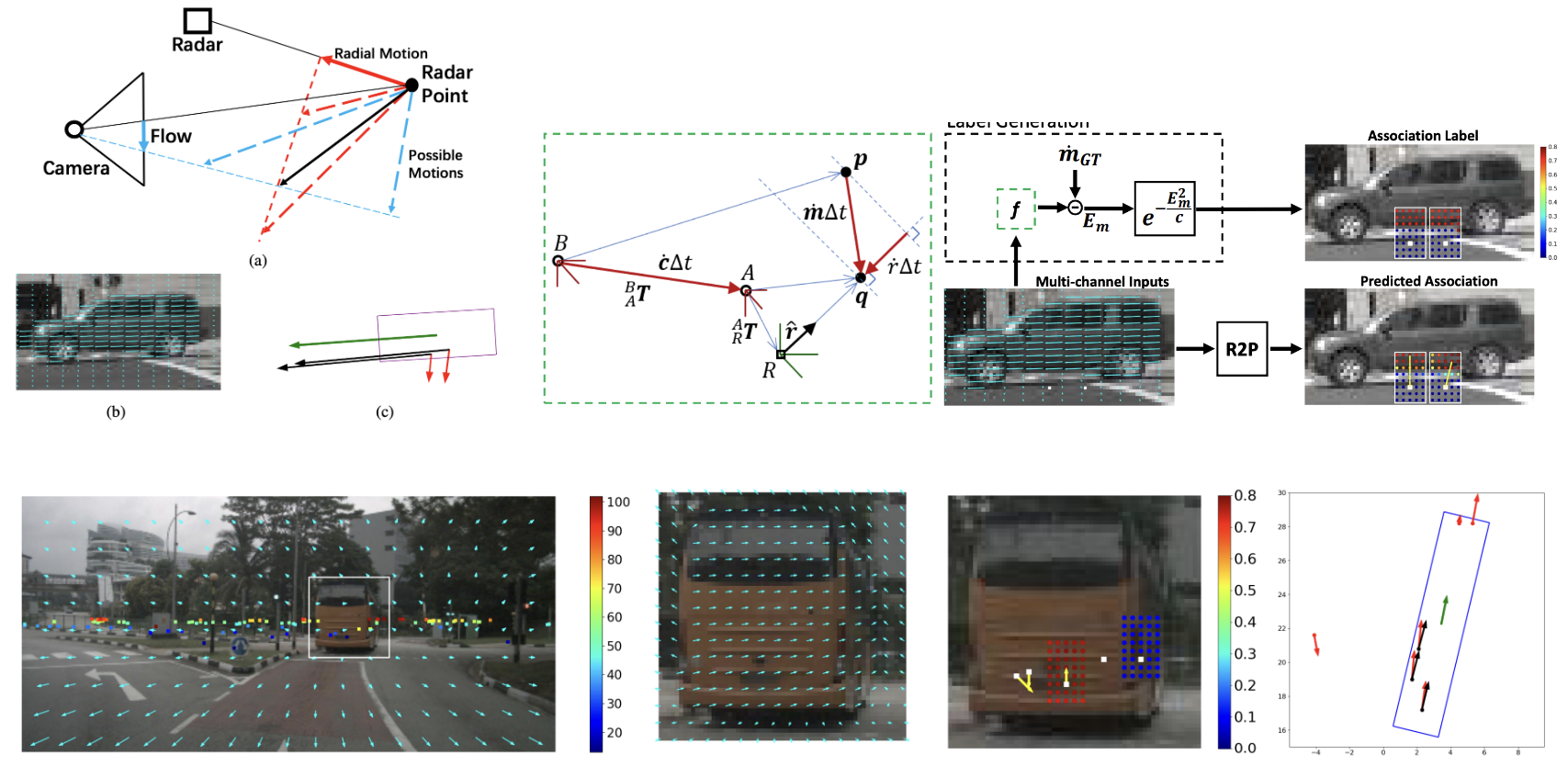
Automotive Doppler radar provides radial velocity but misses tangential components, hampering object velocity estimation and temporal integration in dynamic scenes. We present a closed-form solution for the point-wise full-velocity estimate of Doppler returns using optic flow from camera images. Additionally, we train a network to associate camera and radar returns. Experiments on NuScenes show significant improvements in SoTA velocity estimation.
Sim2Real for Self-Supervised Monocular Depth and Segmentation [ARXIV, 2020]
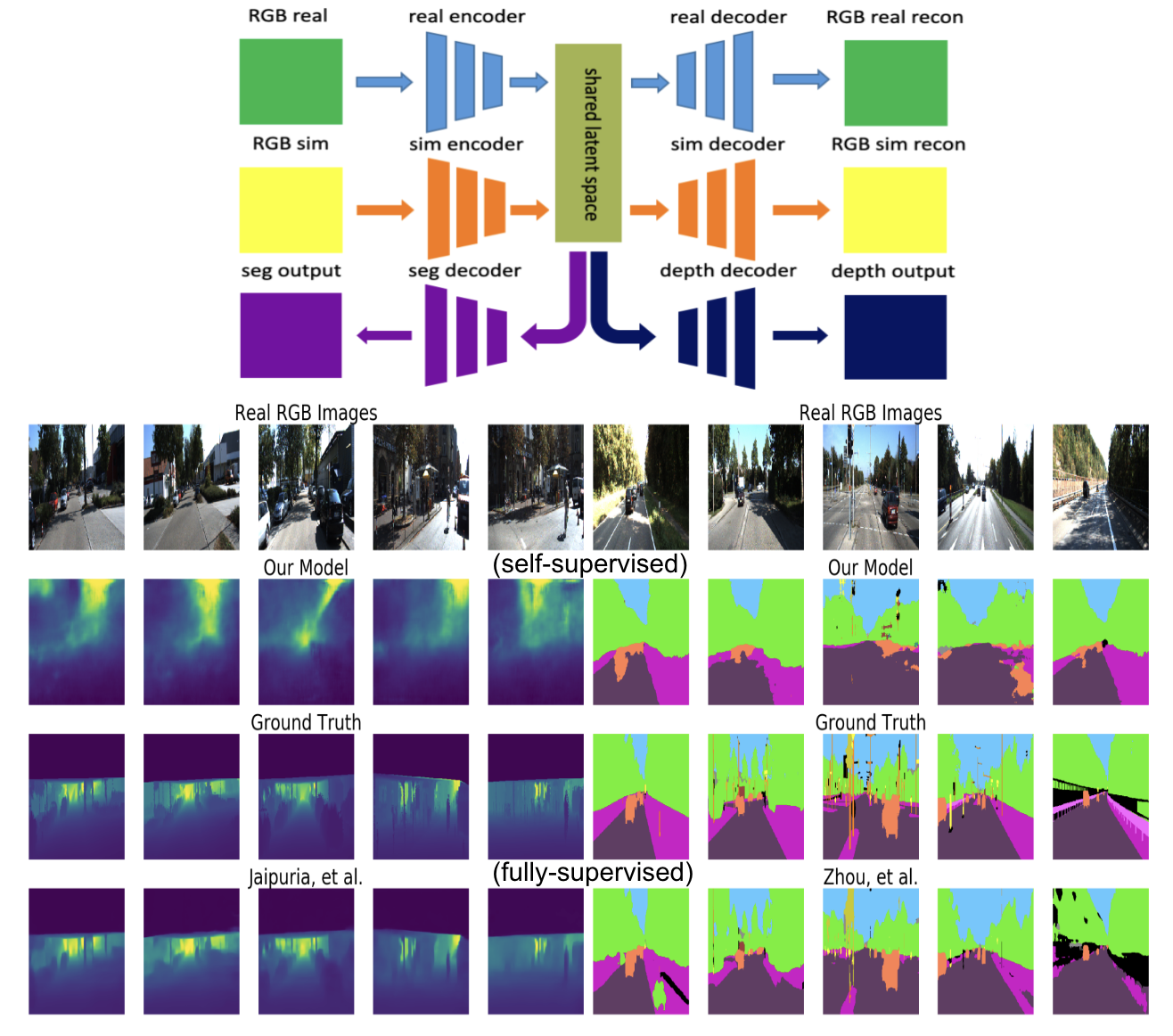
Image based depth estimation and segmentation for AV Perception require large amounts of labelled real world data, which can be costly to obtain. Simulation helps, but networks trained purely on sim fail on real-world imagery. This paper uses a twin-VAE architecture with shared latent space and auxiliary decoders. It transfers training from sim2real without the need for paired training data by using cycle-consistency losses between sim and real. Results are compared with fully supervised methods.
CubifAE-3D Monocular Camera Space Cubification for Auto-encoder based 3D Object Detection [ARXIV, 2020]
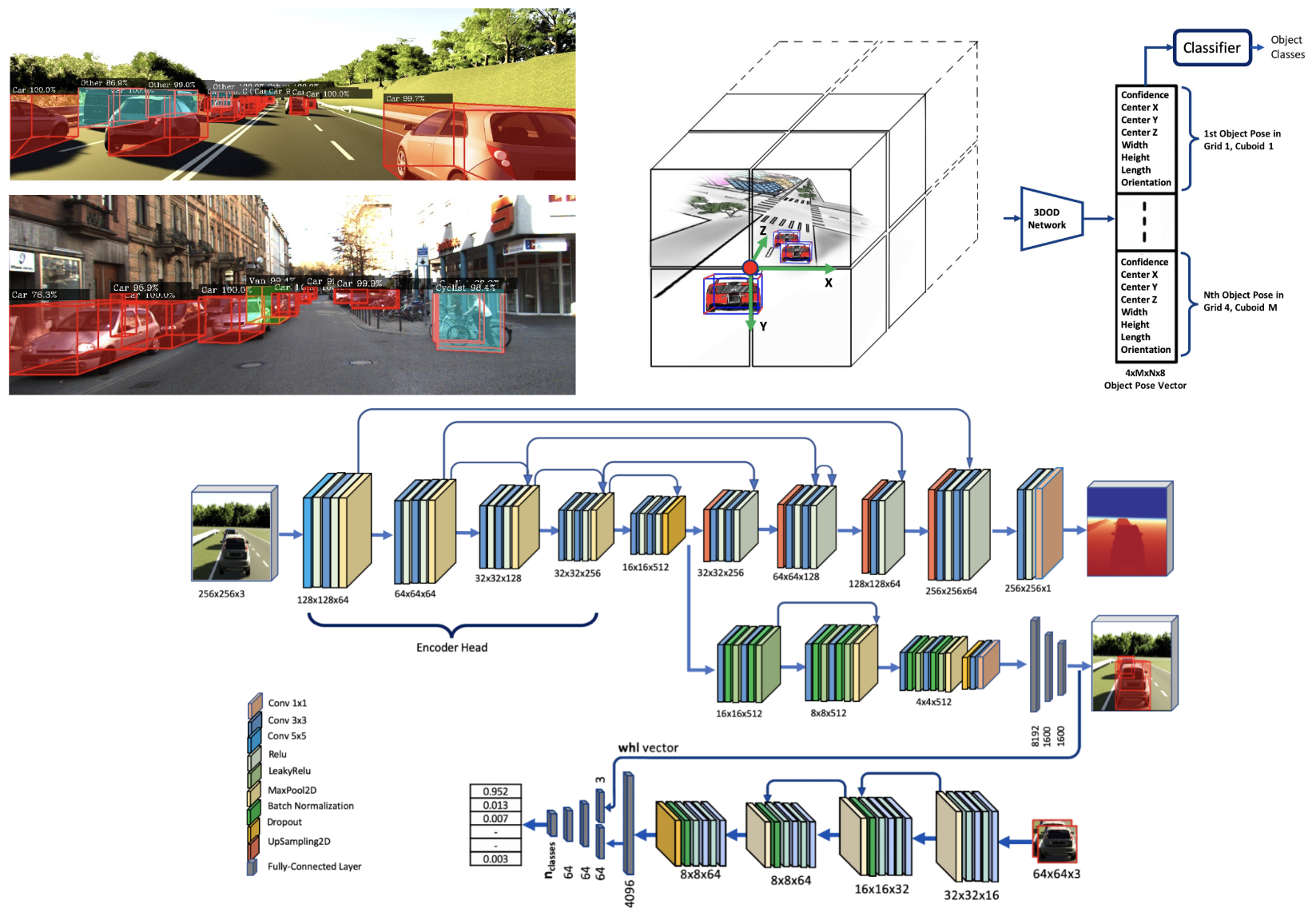
This paper introduces a monocular 3D object detector (3DoD) that operates by cubification of 3D space around the camera, where each cuboid is tasked with predicting N object poses, along with their class and confidence values. An image2depth autoencoder is pre-trained on the data and the encoder is then removed and attached to a 3DoD head. SoTa results are demonstrated in the AV use-case on the KITTI and NuScenes datasets.
Trajectron++: Dynamically-feasible Trajectory Forecasting with Heterogeneous Data [ECCV, 2020]
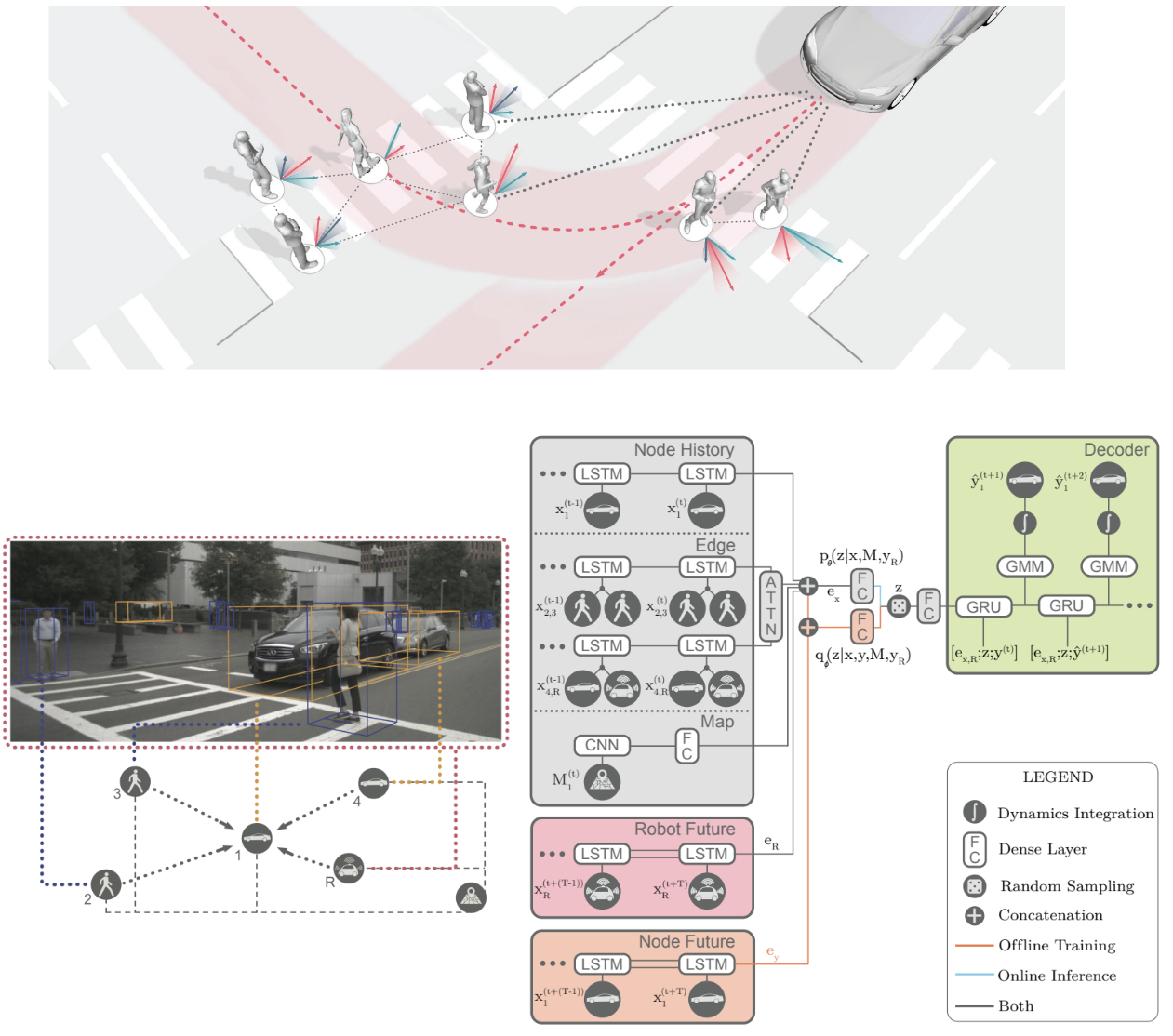
Reasoning about the future motion of humans and other agents around an AV is important for save navigation in crowded environments.This paper presents a trajectory forecasting method that takes into account dynamic constraints and environment (map) information in a graph-structured recurrent model. Trajectron++ is designed to be tightly integrated with robotic planning and control frameworks and can be conditioned on ego-agent motion plans. We demonstrate SoTa results on NuScenes.
Deflating Dataset Bias Using Synthetic Data Augmentation [CVPR, 2020]
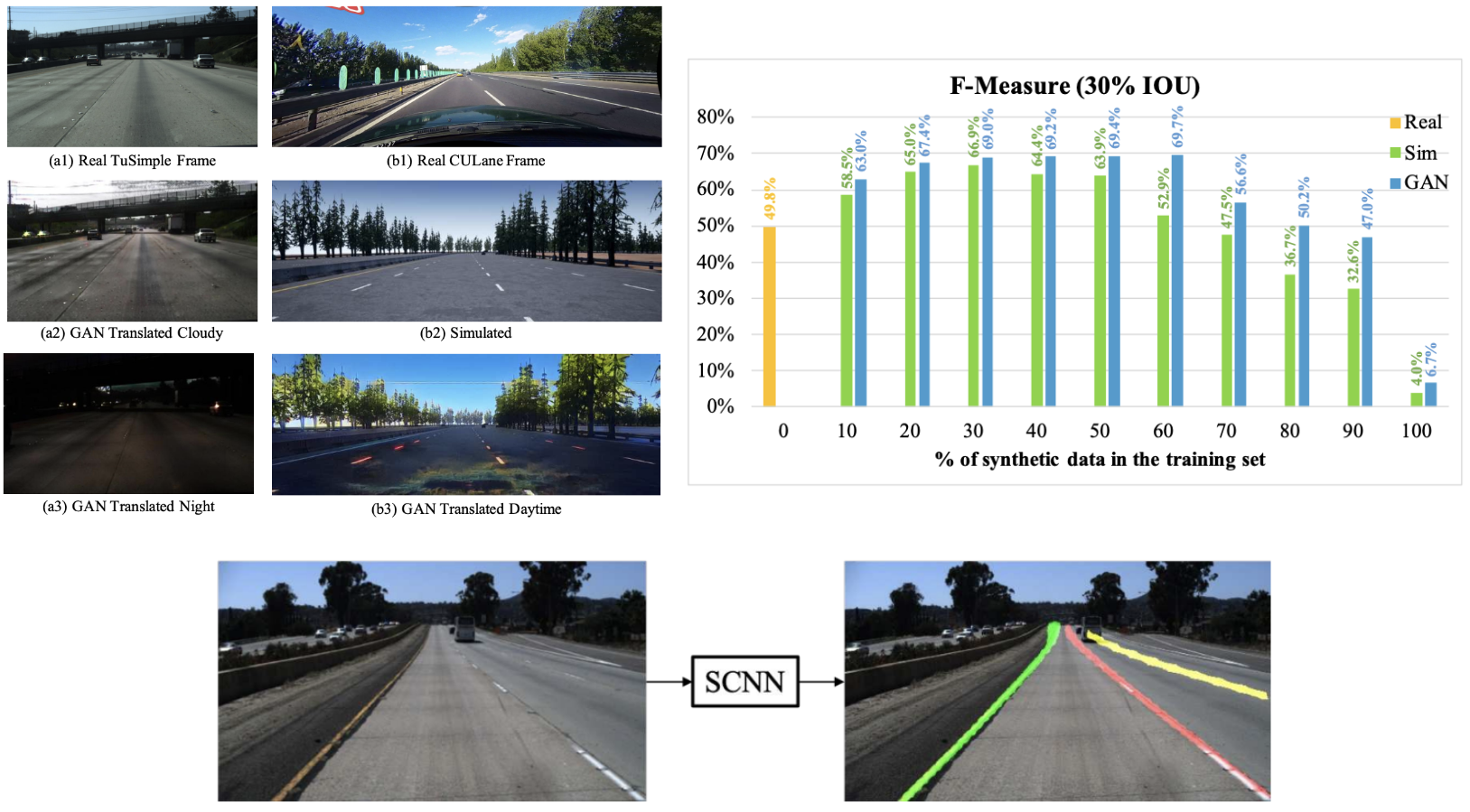
Neural nets for perception tasks often fail to generalize across datasets and capturing long-tail events using real-world data is often impractical.This paper investigates using targeted synthetic data augmentation and sim2real transfer to fill real data gaps. Studies on parking slot detection, lane detection and monocular depth estimation for AVs show that synthetic data and GAN-generated augmentations boost cross-dataset generalization.
Hierarchical Sequence to Sequence Voice Conversion with Limited Data [ARXIV, 2019]
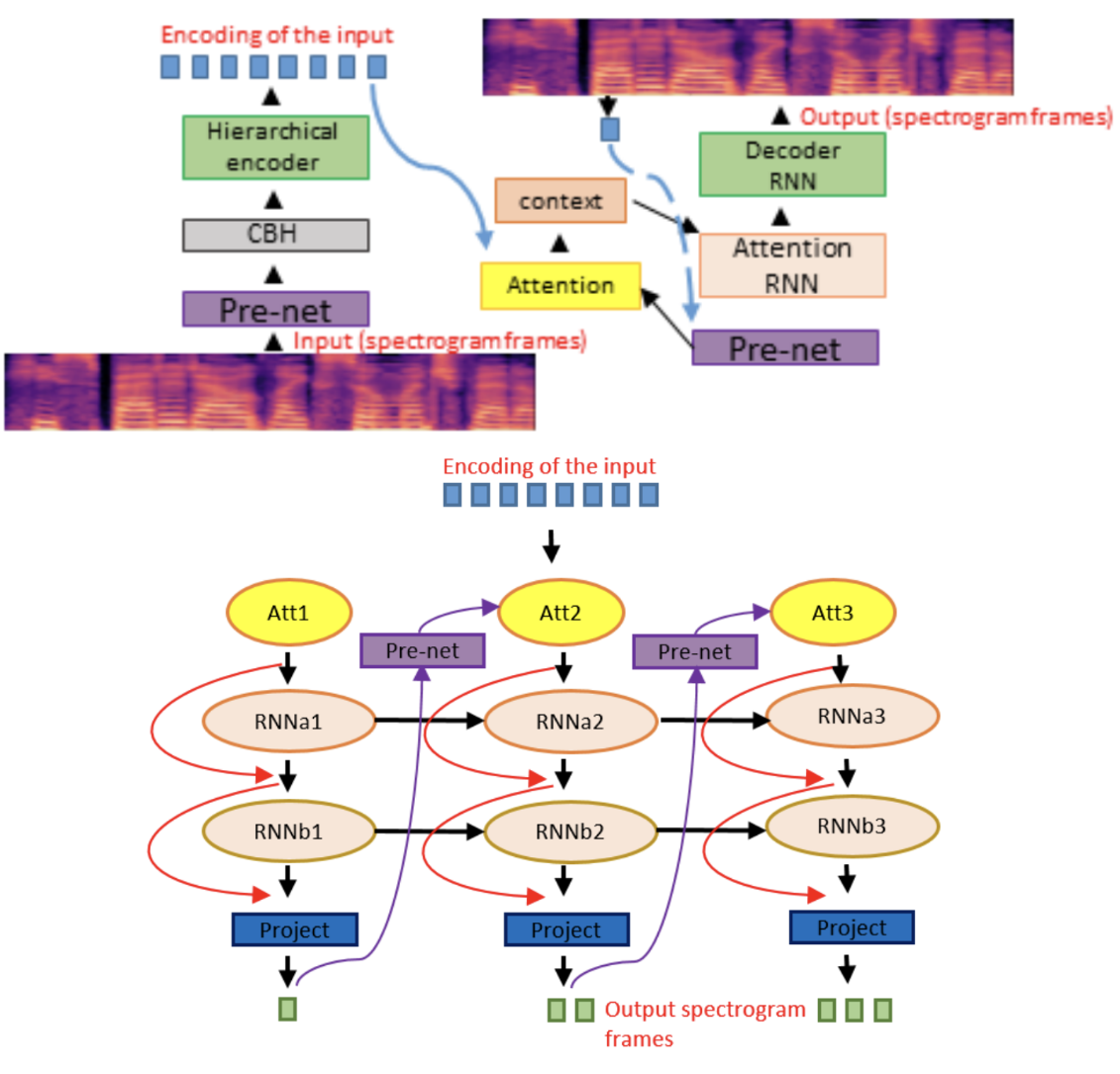
This work demonstrates voice conversion using a hierarchical RNN in an encoder-decoder architecture with attention. The network is pre-trained as an auto-encoder on a large corpus of single-speaker data and subsequently fine-tuned on smaller corpora of paired multi-speaker data. Mel-spectrograms are used as input to the network and output mel-frames are converted to audio using a wavenet vocoder.
GEN-SLAM: Generative Modeling for Monocular SLAM [ICRA, 2019]
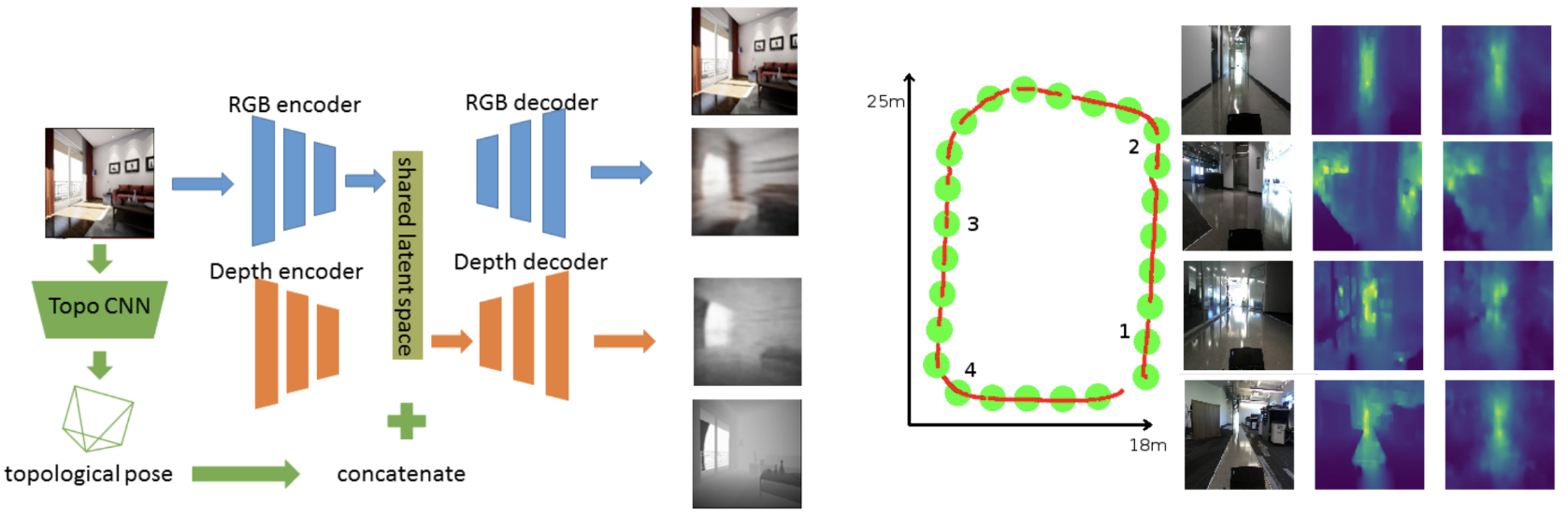
This paper presents a Deep Learning based system for the twin tasks of localization and obstacle avoidance essential to any mobile robot. Our system learns from conventional geometric SLAM, and outputs, using a single camera, the topological pose of the camera in an environment, and the depth map of obstacles around it. We use a CNN to localize in a topological map, and a VAE conditioned on topological location information, to output depth for a camera image. We demonstrate the effectiveness of our monocular localization and depth estimation system on simulated and real datasets.
Publications till 2018 (in reverse chronological order):
• D. Hulens, B. Aerts, P. Chakravarty, A. Diba, T. Goedeme, T. Roussel, J. Zegers, T. Tuytelaars, L. Van Eycken, L. Van Gool, H. Van Hamme, and J. Venneken. The CAMETRON lecture recording system. High Quality Video Recording and Editing with Minimal Human Supervision. International Conference on Multimedia Modeling (MMM), Bangkok, Thailand, 2018.
• R. Aljundi, P. Chakravarty and T. Tuytelaars. Expert Gate – Lifelong Learning with a Network of Experts. International Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii, 2017.
• P. Chakravarty, T. Roussel, K. Kelchtermans, S. Wellens, T. Tuytelaars and L. VanEycken. CNN-based Single Image Obstacle Avoidance on a Quadrotor. International Conference on Robotics and Automation
(ICRA ’17).
• P. Chakravarty, J. Zegers, T. Tuytelaars and H. VanHamme. Active Speaker Detection with Audio-Visual Co-Training. International Conference on Multimodal Interaction (ICMI), Tokyo, November 2016.
• R. Aljundi, P. Chakravarty (equal contribution) and T. Tuytelaars. Who’s that Actor? Automatic Labelling of Actors in TV series starting from IMDB Images. Asian Conference on Computer Vision (ACCV), Taiwan, November 2016.
• P. Chakravarty and T. Tuytelaars. Cross-modal Supervision for Learning Active Speaker Detection in Video. European Conference for Computer Vision
(ECCV), Amsterdam, Oct 2016.
• P. Chakravarty, S. Mirzaei, T. Tuytelaars and H. VanHamme “Who’s Speaking? Audio-Supervised Classification of Active Speakers in Video”. In 2015 International Conference of Multi-modal Interaction (ICMI ’15), Seattle, U.S.A, Nov 2015.
• N. Ho and P. Chakravarty. “Localization on Freeways using the Horizon Line Signature”. In Workshop on Visual Place Recognition in Changing Environments at the International Conference on Robotics and Automation (ICRA ’14), Hong Kong, June 2014.
pdf Demo Video
• P. Chakravarty, D. Rawlinson and R. Jarvis. “Covert Behaviour Detection in a Collaborative Surveillance System”. In 2011 Australasian Conference on Robotics and Automation (ACRA’11),Melbourne, Australia, Dec. 2011.
• P. Chakravarty and R. Jarvis. “External Cameras & A Mobile Robot: A Collaborative Surveillance System”. In 2009 Australasian Conference on Robotics and Automation (ACRA’09), Sydney, Australia, Dec. 2009.
• P. Chakravarty and R. Jarvis. “People Tracking from a Moving Panoramic Camera”. In 2008 Australasian Conference on Robotics and Automation (ACRA’08), Canberra, Australia, Dec. 2008.
pdf Demo Video 1 Demo Video 2 Demo Video 3 Demo Video 4
• P. Chakravarty, A. M. Zhang, R. Jarvis, and L. Kleeman. “Anomaly Detection and Tracking for a Patrolling Robot”. In 2007 Australasian Conference on Robotics and Automation (ACRA’07), Brisbane, Australia, Dec. 2007.
• P. Chakravarty, D. Rawlinson and R. Jarvis. “Person Tracking, Pursuit & Interception by Mobile Robot”. In 2006 Australasian Conference on Robotics and Automation (ACRA’06), Auckland, New Zealand, Dec. 2006.
• P. Chakravarty and R. Jarvis. “Panoramic Vision and Laser Range Finder Fusion for Multiple Person Tracking”. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’06), Beijing, China, Sep. 2006.
• P. Chakravarty and R. Jarvis. “Multiple Target Tracking for Surveillance: A Particle Filter Approach”. In IEEE International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP’05), Melbourne, Australia, Dec. 2005.
• D. Rawlinson, P. Chakravarty and R. Jarvis. “Distributed Visual Servoing of a Mobile Robot for Surveillance Applications”. In 2004 Australasian Conference on Robotics and Automation (ACRA’04), Canberra, Australia, Dec. 2004.
